© thethomason
监督学习
假设我们有一个数据集,给出了俄勒冈州勃兰特地区47个房子的住房面积和价格:

我们可以用散点图来描述上面的这些数据:

当我们想根据这个图片了解某个任意房屋面积下的房子价格的时候,依靠这个图片是办不到的。因此我们需要建立一个函数来解决这个问题。可以使用我们在高中时期学过的回归函数对这个模型进行求解。
解题步骤:
令 $x^{(i)}$ 代表 "$input$" 变量(在这个例子中的住房面积),输入变量也可以称作输入$特征$
令 $y^{(i)}$ 代表我们需要去预测的 "$output$" 或者$目标变量$(房屋价格)。一个数对 $(x^{(i)},y^{(i)})$ 被称作是一个训练样本
- ${(x^{(i)},y^{(i)});i=1,...,m}$ 被称作一个$训练集$。这个例子中 $m=47$
【特别注意】角标 "(i)" 仅仅是一个训练集的索引,和指数并没有任何关系。
我们将使用 $\mathcal{X}$ 代表输入值空间,用 $\mathcal{Y}$ 表示输出值空间。在这个例子中,$\mathcal{X}=\mathcal{Y}=\mathbb{R}$。
为了更加正式的描述监督学习的定义,我们可以这样说:
给定一个目标,一个训练集,学习一个函数$h:\mathcal{X \mapsto Y}$。
如果满足这个映射关系,我们说$h(x)$是与之对应的$y$的一个很好的预测器。由于历史原因,函数$h$被叫做是假设。整个过程的流程如下所示:

- 当目标变量是连续的时候(比如在房价模型中)我们把它归类到为回归问题。
- 当目标变量$y$不连续的时候(比如给出房屋面积,让我们去预测这个房子是一个普通的小区住房还是别墅)我们把它归类到分类问题。
Part I 线性回归
为了让我们的房价模型更加有趣,我们考虑丰富一下我们的数据集,增加一个卧室数量的特征:
现在我们的输入变了变成了二维的空间向量(因为有两个特征:面积,卧室数量)。另外,我们用符号来表示该模型的时候,$x_1^{(i)}$ 表示第 $i$ 个房屋的面积,$x_2^{(i)}$ 表示第 $i$ 个房子的卧室数量(通常来讲,设计一个学习算法,选择多少个输入特征完全由你自己决定,所以如果你是外地人,想要在勃兰特购买房子的话,你可以收集其他的房屋信息,比如是否有一个炉灶,卫生间的数目等。我们后面也会讲到多个特征的选取,但是现在仅考虑给出的两个特征)。
为了能够让计算机执行监督学习算法,我们需要决定如何去表示函数(假设)$h$ 。作为一个最初的选择,我们决定估计 $y$ 是一个关于 $x$ 的线性函数:
$$ h_\theta(x)=\theta_0+\theta_1x_1+\theta_2x_2
$$ 其中,$\thetai$ 称为参数(也叫做权重),它用来界定描述 $\mathcal{X}$ 映射到 $\mathcal{Y}$ 的线性函数的空间。当没有什么疑惑的时候,我们把 $\theta$ 写成映射关系的角标并记作 $h\theta(x)$ ,简写为 $h_\theta(x)$ 。为了简化我们的式子,令 $x_0=1$(这一项表示截距),简写如下:
$$ h(x)=\sum\limits_{i=0}^n\theta_ix_i=\theta^Tx
$$ 等号的右侧,$\theta$ 和 $x$ 都是向量,$n$ 表示输入变量的个数(而不是 $x_0$ 个数),为了便于理解,输入矩阵可能长下面这个样子:
$$ \begin{matrix} x{11} & ... & x{1n} \\ . & & . \\ . & . & . \\ . & & . \\ x{m1} & ... & x{mn} \end{matrix}
$$ 而 $\theta$ 长这个样子:
$$ \begin{matrix} \theta{1}\\ \theta{2}\\ . \\ . \\ \theta_{n} \end{matrix}
$$ 现在,给定训练集 $x$ ,我们如何选取和学习参数 $\theta$ ,这就是监督学习要做到事情了。
一个合理的解决方案就是令 $h(x)$ 不断的接近其真值 $y$ ,至少我们在训练的例子中是这样做的。这句话好说,人也可以理解,但是机器不能,现在就可以公式化,让机器可以理解:定义一个函数,它用来衡量对每个 $\theta$ 取值 $h(x^{(i)})$ 和 $y^{(i)}$ 的误差是多少,也就是下面的损失函数:
$$ J(\theta)=\frac 1 2 \sum\limits{i=1}^m{(h\theta(x^{(i)})-y^{(i)})^2}
$$ 如果你之前接触过线性回归,你可能会意识到这个损失函数和最小二乘法相似,并有此产生了一个普通的最小二乘回归模型。无论你之前是否了解过,现在我们继续,最终我们会展示这是非常广泛的算法族中的一个特殊情况。
最小均方(LMS)算法
为了能够得到使 $J(\theta)$ 最小的 $\theta$ ,我们对上面的算法需要先做一个假想的 $\theta$ (也就是说我们猜想,$\theta$ 在这个取值下,$J(\theta)$ 可以取到最小值,当然假想可能不正确,然后我们重复的对 $\theta$ 进行取值,令 $J(\theta)$ 不断的变小,直到我们不论对 $\theta$ 取何值,都能得到一个相同的 $J(\theta)$ )。特别的,我们考虑使用梯度下降算法,这个算法是选取了一个初始的 $\theta$ 然后重复的更新目标值:
$$ \theta_j:=\theta_j-\alpha\frac{\partial}{\partial\theta_j}J(\theta)\\ “:=”这个符号表示的是计算机语言中法赋值符号
$$ (如果你的计算机是多核的话,可以同时的执行对于 $j=0,...n$ 所有取值下的更新)。
其中,$\alpha$ 称为学习率,这是一个非常自然的算法,每次按照梯度下降最快的方向前进一小步(对 $J$ 求梯度)。
进一步解释说明这个算法,我们需要计算出在等号的右侧的偏导数。我们首先计算只有一个训练样本 $(x,y)$ 的情况,在这种情况下我们可以忽略掉 $J$ 的求和符号,然后进行推广:
$$ \begin{align*} \frac{\partial}{\partial\thetaj}J(\theta) &=\frac{\partial}{\partial\theta_j}\frac 1 2 {(h\theta(x)-y)^2}\\ &=2·\frac 1 2 {(h\theta(x)-y)}·\frac{\partial}{\partial\theta_j}(h\theta(x)-y)\\ &={(h\theta(x)-y)}·\frac{\partial}{\partial\theta_j}(\sum\limits{i=1}^n \thetaix_i-y)\\ &=(h\theta(x)-y)x_j \end{align*}
$$
对于整个训练样本,给出的更新规则如下:
$$ \thetaj:=\theta_j-\alpha(h\theta(x^{(i)})-y^{(i)})x_j^{(i)}
$$
这个规则被称为是LMS更新规则(least mean squares)有时也被称为是 Widrow-Hoff 学习规则。这个规则有几个直观、自然的属性。举例来说,更新的快慢取决于误差项 $h\theta(x^{(i)})-y^{(i)}$ ;因此,如果我们一开始对 $\theta$ 的取值误差很小的话,我们发现几乎不需要更改参数 $\theta$,相反,如果误差较大,那么参数会发生较大的变化来使预测值 $h\theta(x^{(i)})$ 更加的接近真实值 $y^{(i)}$。
我们已经对一个训练样本进行了扩展。有两种方法可以对这个算法进行修改,使其可以训练多个样本。首先用下面的算法代替之前的算法:
重复计算过程直到更新稳定{
$$ \thetaj:=\theta_j-\alpha\sum\limits{i=1}^m(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} \\(遍历所有的j)
$$
}
这个阅读器可以很容易的确定求和项的数目。这是对原始的损失函数应用了一个简单的梯度下降。这个方法每进行一步就会遍历所有的样本,这个算法被称为批量梯度下降。补充一下,梯度下降容易陷入局部最优解,而我们对这个模型简单化,我们选择的是只有一个全局最优解,没有局部最优,因此梯度下降算法总是能够找到一个最小值。(如果有多个局部最优解,需要考虑优化算法)事实上,$J$ 是一个凸二次函数。这里有一个关于运行梯度下降算法求二次函数最小值的例子。
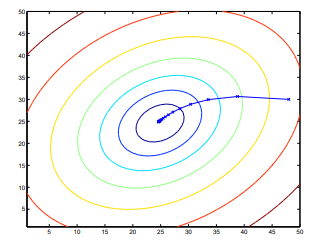
上面的椭圆表示的是二次函数的轮廓图(曲线图)。蓝色的曲线表示的是梯度下降的路径,选取的初始值是(48,30)。图中的 $x$ (蓝色的短直线)标记了 $\theta$ 的连续下降路径。
当我们运行批量梯度下降寻找合适的 $\theta$ 的时候(之前的房价模型),我们可以得到一个一个房屋的预测价格函数(关于住房面积),最终求得 $\theta0=71.27, \theta_1=0.1345$。画出 $h\theta(x)$ 关于 $x$(住房面积) 的函数图像,如下:
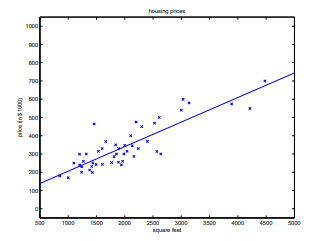
如果加入卧室数量这个输入特征,可以得到 $\theta_0=89.60, \theta_1=0.1392, \theta_2=-8.738$ 。
上面的计算结果是根据批量梯度下降算法得到的。另一种方法也可以取得很好的效果,其数学描述如下:
Loop {
for i = 1 to m, {
$$ \thetaj:=\theta_j-\alpha(h\theta(x^{(i)})-y^{(i)})x_j^{(i)} \\ (遍历所有的j)
$$
}
}
在这个算法中,重复的运算更新规则,每次训练一个样本,然后根据这一个训练样本的误差按照梯度的方向更新一次参数,这个算法叫做随机梯度下降法(也叫做梯度上升法)。批量梯度下降发法每次更新参数都需要遍历所有的训练样本,如果训练集的样本数目 $m$ 很大,随机梯度下降法的优势就体现出来了,然后根据训练样本继续更新参数。通常,随机梯度下降可能得到的 $\theta$ 并不是全局最优解,而是和全局最优解很相近的一个数,随机梯度下降法的收敛速度要比批量梯度下降法快很多。虽然随机梯度下降法无法得到一个全局最优解,但是在实际应用中,这个近似值已经足够了。正是由于这个原因,在庞大的数据集下,随机梯度下降法可以表现出比批量梯度下降法更优秀的效果。
正规方程(The normal equations)
梯度下降法给出了一个最小化 $J$ 的方式。现在讨论第二种方式,这次计算用直接的方式来进行计算最小化,不采用迭代算法。我们将显式的取 $\theta_j$ 的导数来最小化 $J$ ,将 $\theta_j$ 设置为 $0$ 。为了能够不浪费大量的纸张,只是在纸上写矩阵的求导运算,我们介绍几个符号来代替这些求导工作。
矩阵求导
对一个函数 $f:\mathbb{R}^{m×n}\mapsto\mathbb{R}$ ,其表示一个 $m×n$ 的矩阵到实数的计算过程,对 $f$ 关于 $A$ 的求导,定义如下:
$$ \nablaAf(A)=\left[\begin{array}{cc} \frac{\partial f}{\partial A{11}} & ... & \frac{\partial f}{\partial A{1n}} \\ . & & . \\ . & . & . \\ . & & . \\ \frac{\partial f}{\partial A{m1}} & ... & \frac{\partial f}{\partial A_{mn}} \end{array}\right]
$$ 因此,$\nablaAf(A)$ 自身是一个 $m×n$ 的矩阵,第 $(i,j)$ 个元素是 $\partial{f}/\partial{A{ij}}$ 。举例来说,假设 $A=\left[\begin{array}{cc}A{11}&A{12} \\A{21}&A{22}\end{array}\right]$ 是一个 $2×2$ 的矩阵,函数 $f:\mathbb{R}^{2×2}\mapsto\mathbb{R}$ 如下:
$$ f(A)=\frac{3}{2}A{11}+5A{12}^2+A{21}A{22}
$$ 其中,$A_{ij}$ 表示矩阵的第 $(i,j)$ 个元素,我们有下面的推导:
$$ \nablaAf(A)=\left[\begin{array}{cc}\frac{3}{2}&10A{12} \\A{22}&A{21}\end{array}\right]
$$ 另外,介绍一下矩阵的迹(trace)运算符号,记作 “tr”。对于一个 $n×n$ 的方阵 $A$,它的迹被定义为对角线元素的和:
$$ trA=\sum\limits{i=1}^nA{ii}
$$ 如果 $a$ 是一个实数(i.e.,$a$ 是一个 $1*1$ 的矩阵),那么 $tr \space a= a$ 。(如果你之前没有见过这个操作符号,你可以把 $A$ 的迹想成 $tr(A)$,或者 “trace” 函数在矩阵 $A$ 上的一个作用。通常情况下,我们不写括号。)
对于两个矩阵 $A$ 和 $B$ 来说,迹运算下面的几个运算性质,$AB$ 是一个方阵,我们可以得到 $trAB=trBA$(你可以自己验算)根据这个式子可以推导出下面的结论:
$$ trABC = trCAB = trBCA \\ trABCD = trDABC = trCDAB = trBCDA
$$ 下面的性质也是很好证明的,其中 $A$ 和 $B$ 是方阵,$a$ 是一个实数。
$$ trA = trA^T\\ tr(A + B) = trA + trB\\ tr\ aA = a\ trA
$$ 现在对下面的公理不加以证明(这些矩阵的求导运算现在可能不会用到,但是之后可能会用到)。等式(4)仅适用于非奇异性矩阵 $A$,其中 $|A|$ 表示矩阵 $A$ 对应行列式的值。
$$ \begin{alignat}{2} \nablaAtrAB &= B^T \\ \nabla{A^T} f(A) &= (\nabla_Af(A))^T \\ \nabla_AtrABA^TC &= CAB + C^TAB^T \\ \nabla A|A| &= |A|(A^{−1})^T \\ \end{alignat}
$$ 进一步说明,假设我们有一个固定的矩阵 $B \in R^{n×m}$ 。我们可以根据 $f(A)=trAB$ 定义一个函数 $f:\mathbb{R}^{m×n}\mapsto\mathbb{R}$ 。为了使这个定义起作用,因为如果 $A ∈ R^{m×n}$ ,那么 $AB$ 就是一个方阵,然后我们可以应用上面的迹运算;因此,$f$ 实际上执行了一个从 $\mathbb{R}^{m×n}$ 到 $\mathbb{R}$ 的运算。我们可以用我们的矩阵求导的定义来计算 $\nablaAf(A)$ ,它将由一个 $m×n$ 的矩阵构成。等式 (1)表示了这个矩阵的第 $(i,j)$ 个元素等于 $B^T$ 的第 $(i,j)$ 个元素,或者,记作 $B{ji}$。
等式(1)到(3)的证明是非常简单的,留给读者自行证明。等式(4)可以利用逆矩阵的伴随矩阵得到。
未完待续 ...
作者无力同时维护两个网站,查看最新更新,请前往个人博客